 The linguistic database - the universal knowledge base
The linguistic database - the universal knowledge base
InfoCodex is based on an advanced new technology for text analysis and cross-lingual content recognition (patented in the EU and U.S.A.).
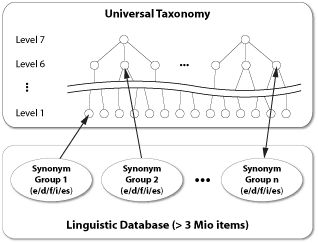
Words or expressions (groups of words such as "European
Union", "Enterprise Search Engine" etc.) present in the
text are matched against InfoCodex's linguistic database, which comprises
more than 3 million words/expressions which are structured into cross-lingual
synonym groups. These synonym groups point to a node in a universal
taxonomy (ontology) characterizing the meaning of the matched synonym.
This language-independent information is then used to extract the content
of the document.
Cross-lingual universal knowledge repository
The central multi-lingual knowledge base (linguistic database) is the result of combining and harmonizing knowledge repositories from established works such as the WordNet (Princeton University), EuroVoc, AgriVoc, JuriVoc, the International Classification for Standards (ICS), financial taxonomies and many other sources.