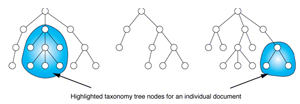
Bei der Analyse eines einzelnen Dokuments
werden alle Knoten im Taxonomiebaum markiert, welche durch die in der
Textanalyse erkannten Wörter/Ausdrücke
angesprochen werden. Die Gesamtheit aller markierten Knoten zeigt die
thematischen Gebiete an, die durch das Dokument abgedeckt werden.
Die thematischen Gebiete der verschiedenen Dokumente werden
dann auf einen 100-dimensionalen Inhaltsraum projiziert, dessen Dimensionen
optimal auf den Gesamtinhalt aller Dokumente abgestimmt sind. Die Kategorisierung
der Dokumente wird anschliessend durch ein selbst-organisierendes neuronales
Netz (Kohonen-Map) vollzogen, das die Dokumente in einem sachlogisch
aufgebauten „Bücherregal“ ablegt. Das neuronale Netz
liefert gleichzeitig ein wissenschaftlich fundiertes
Ähnlichkeitsmass auf informationstheoretischer
Grundlage, welches den Inhaltsvergleich von verschiedenen Dokumenten
ermöglicht.
Die Inhaltserkennung und Kategorisierung erfolgt über
die Sprachgrenzen hinweg. So wird beispielsweise erkannt, dass die englische
Übersetzung eines deutschen, französischen, italienischen
oder spanischen Dokuments praktisch den gleichen Inhalt hat wie das
Originaldokument.
Im Gegensatz zu anderen Systemen erfolgt die Kategorisierung
in InfoCodex vollautomatisch, d.h. ohne menschliches Zutun. Diese Funktionalität
eliminiert das mühsame und aufwendige Trainieren einer Dokumenten-Kategorisierung
mit Musterkollektionen – ein entscheidender Vorteil.