 Die Linguistische Datenbank - die universelle Wissensbasis
Die Linguistische Datenbank - die universelle Wissensbasis
InfoCodex basiert auf einer fortschrittlichen
neuen Technologie für Textanalyse und sprachübergreifende Inhaltserkennung
(patentiert in Europa und den USA).
Im Text vorkommende Wörter oder Ausdrücke (Wortgruppen wie
"Europäische Union", "Unternehmens-Suchmaschine" etc.) werden mit der
linguistischen Datenbank von InfoCodex abgeglichen. Diese umfasst mehr
als drei Millionen Wörter/Ausdrücke, die nach sprachübergreifenden Synonymgruppen
klassiert sind. Die Synonymgruppen weisen auf einen Knotenpunkt in einer
universellen Taxonomie (Ontologie), welche die Bedeutung der abgeglichenen
Synonyme charakterisiert. Diese von der Sprache unabhängige Information
wird daraufhin verwendet, um den Inhalt des Dokuments einzuordnen.
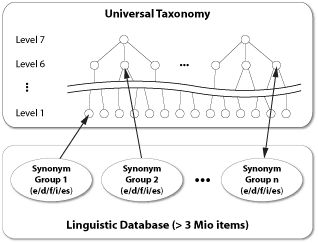
Sprachübergreifender universeller Wissensspeicher
Die zentrale mehrsprachige linguistische Datenbank (Wissensspeicher) resultiert aus dem Kombinieren und Harmonisieren von anerkannten linguistischen Werken wie dem WordNet (Princeton University), EuroVoc, AgriVoc, JuriVoc, DIN, der „International Classification for Standards“ (ICS), Finanztaxonomien und vielen anderen Quellen.